🩷 방문자 추이
🏆 인기글 순위
티스토리 뷰
파이썬으로 네이버 뉴스 크롤링을 해봅시다!
제가 크롤링해볼 네이버 뉴스 링크는 아래와 같습니다. 댓글이 많이 달린 뉴스!!
https://news.naver.com/main/ranking/popularMemo.naver
네이버 뉴스
정치, 경제, 사회, 생활/문화, 세계, IT/과학 등 언론사별, 분야별 뉴스 기사 제공
news.naver.com
reqeusts, BeautifulSoup을 통해 뉴스의 html 소스코드를 파싱해옵니다.
import requests
from bs4 import BeautifulSoup
url = "https://news.naver.com/main/ranking/popularMemo.naver"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
이 때, 헤더를 붙이지 않으면 아래와 같은 에러가 나므로 주의 !
ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
개발자도구를 열어 뉴스 카드의 소스코드를 살펴보니, 언론사마다 rankingnews_list가 동일하게 들어있습니다.
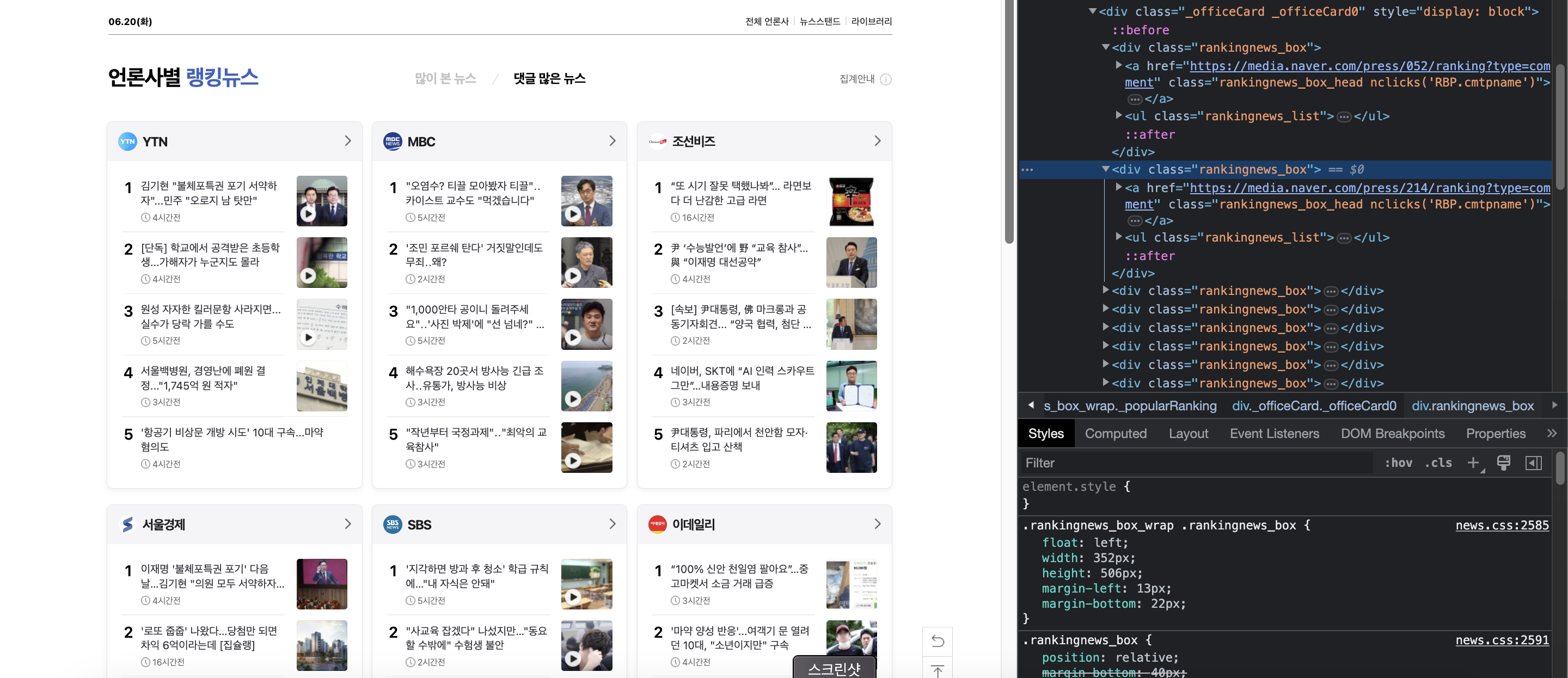
랭킹뉴스 리스트를 가져와보니, 페이지에는 12개의 언론사별 랭킹뉴스가 있는데, 소스에는 78개가 들어있네요.
newslist = soup.select(".rankingnews_list")
len(newslist)
제대로 잘 가져와진게 맞는지 확인해보기 위해 페이지 맨 첫번째에 있는 언론사 랭킹과 맨 마지막에 있는 언론사 랭킹을 출력해봅니다.
첫번째 언론사는 YTN이고, 마지막 언론사 는 MBN의 뉴스네요.

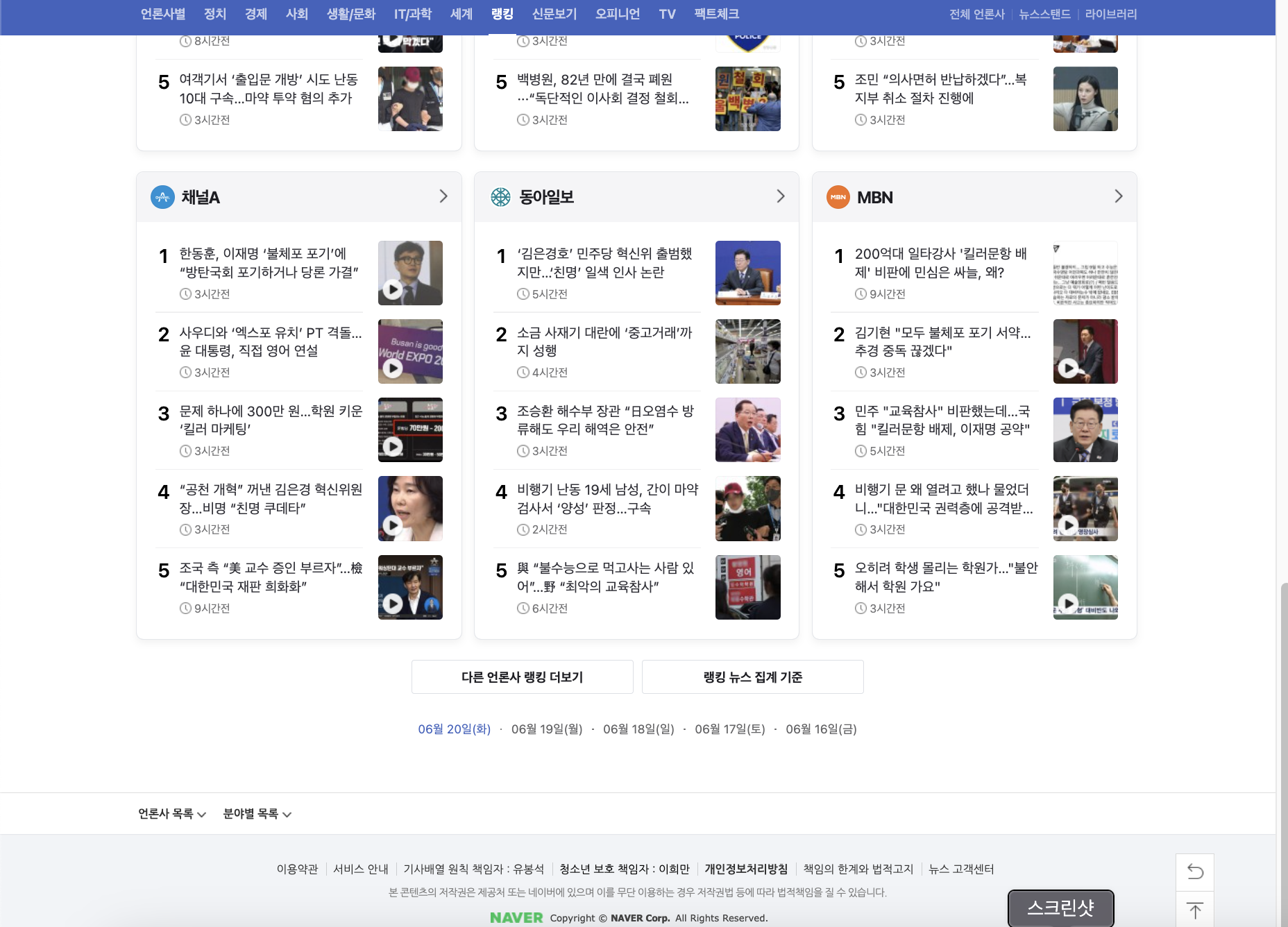
newslist에 들어있는 첫번째 인덱스의 뉴스들과 11번째인덱스(12번째 언론사) 뉴스들을 출력해보니 페이지에 보이는 것과 순서가 동일한 것을 알 수 있습니다.
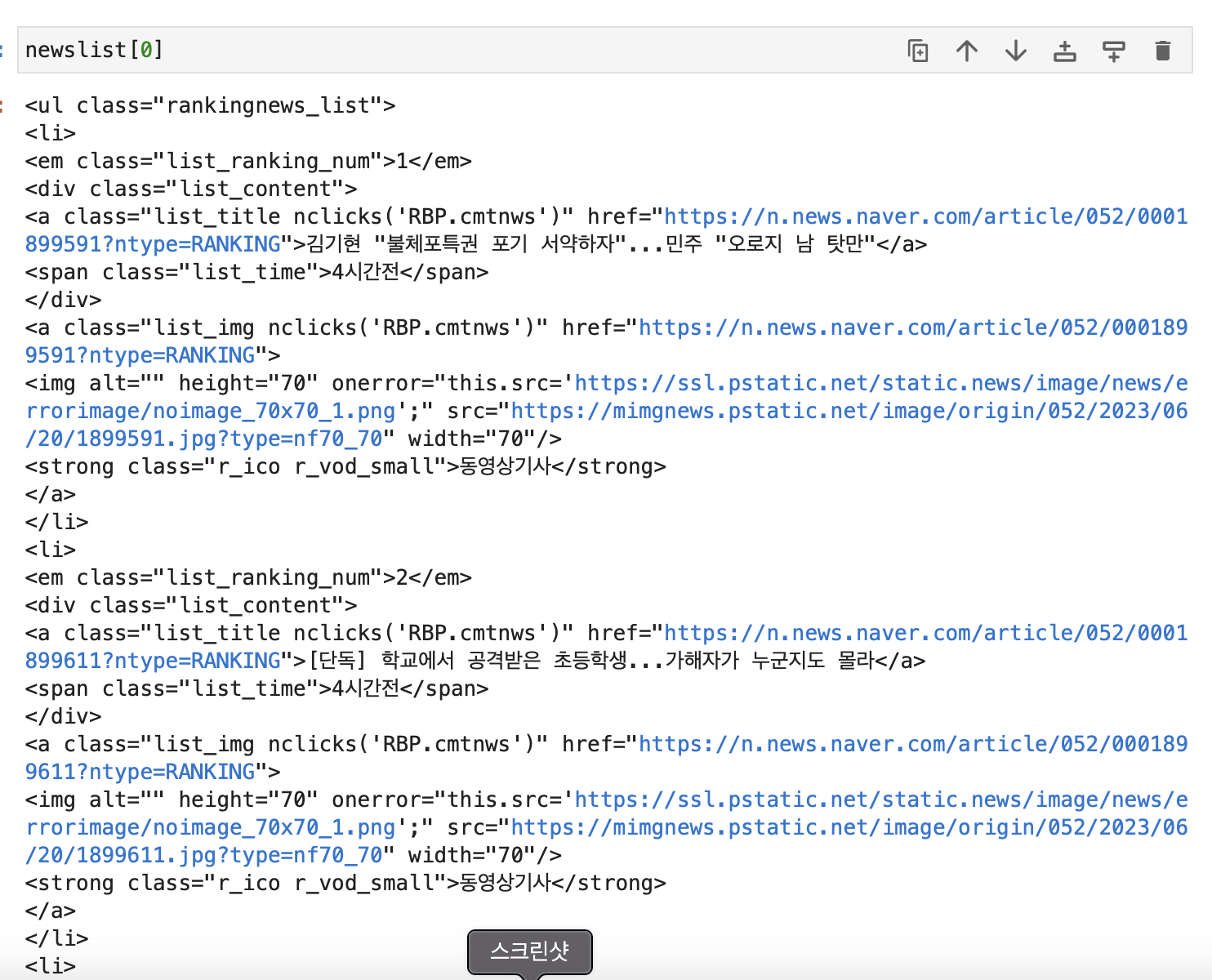

13번째부터 보이지않는 뉴스는 머니투데이 언론사의 뉴스로, style="display: none"으로 안보이게 처리해두었네요.

이제 뉴스내용을 수집해봅시다.
각 rankingnews_list에는 뉴스내용을 담고있는 li태그들이 5개씩 있습니다.
첫번째 li 태그를 출력해 어떤 내용들을 가져올 수 있는지 확인해봅니다.
뉴스랭킹(list_ranking_num), 뉴스링크와 뉴스제목(list_title), 작성시간(list_time), 뉴스 썸네일(img)이 있네요.
뉴스 작성시간대도 "4시간전"이라고 쓰여져있으니, 이걸 가져오기에는 또 처리를 해줘야하기 때문에.. 링크를 들어가서 가져오는 것이 편할 것 같습니다. 또, 뉴스의 상세한 내용도 링크를 들어가서 확인할 수 있겠습니다.

뉴스 언론사가 달라도 태그는 동일할테니, for문을 돌려 똑같이 수집하면 됩니다.
뉴스랭킹(list_ranking_num), 뉴스링크와 뉴스제목(list_title), 뉴스 썸네일(img)을 가져옵니다.
# 언론사마다
for news in newslist:
# 5개의 상위랭킹 뉴스를 가져옴
lis = news.findAll("li")
# 5개 뉴스 데이터 수집
for li in lis:
# 뉴스랭킹
news_ranking = li.select_one(".list_ranking_num").text
# 뉴스링크와 제목
list_title = li.select_one(".list_title")
news_title = list_title.text
news_link = list_title.get("href")
# 뉴스 썸네일
try: news_img = li.select_one("img").get("src")
except: news_img = None
print("랭킹: ", news_ranking)
print("제목: ", news_title)
print("링크: ", news_link)
print("썸네일: ", news_img)
위 코드를 보면 news_img를 가져올 때 try except문을 달아놨는데,
아래와 같이 이미지가 없는 뉴스들이 있기 때문에.. try except로 예외처리를 해둔 것입니다..
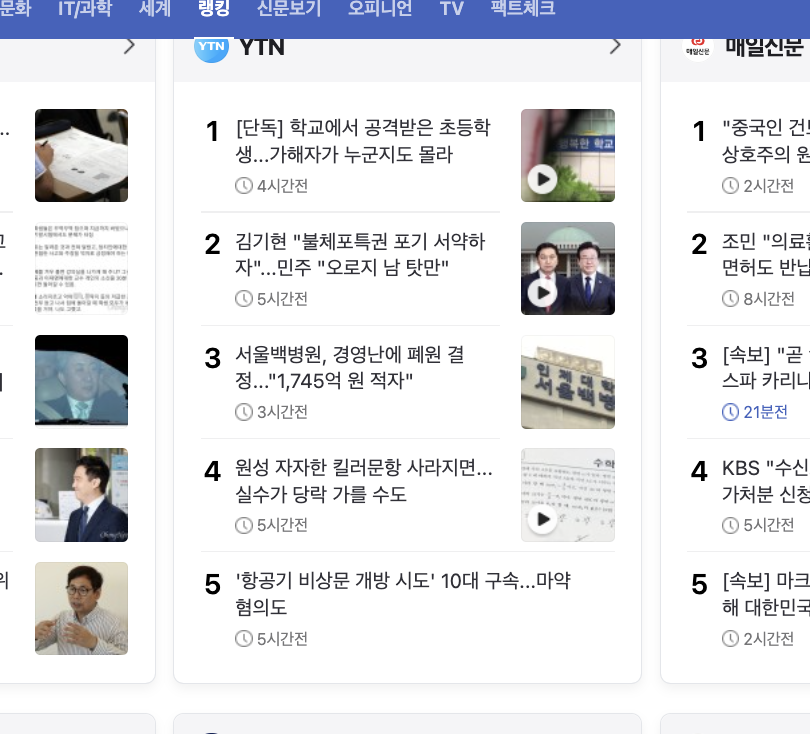
출력하여 정상적으로 가져오고 있는지 확인해봅시다!

정상적으로 데이터를 가져오고 있는 것을 확인했으니, 이제 데이터를 리스트로 저장해봅시다.
처음 for문에 있는 news_list 옆에 [:12]을 추가했습니다.
페이지와 동일하게 12개의 언론사랭킹 뉴스 리스트만 가져오려고 하기 위함입니다.
newsData = []
# 언론사마다
for news in newslist[:12]:
# 5개의 상위랭킹 뉴스를 가져옴
lis = news.findAll("li")
# 5개 뉴스 데이터 수집
for li in lis:
# 뉴스랭킹
news_ranking = li.select_one(".list_ranking_num").text
# 뉴스링크와 제목
list_title = li.select_one(".list_title")
news_title = list_title.text
news_link = list_title.get("href")
# 뉴스 썸네일
try:news_img = li.select_one("img").get("src")
except: news_img = None
# 저장
newsData.append({
'ranking': news_ranking,
'title': news_title,
'link': news_link,
'img': news_img
})
12개의 언론사 * 상위랭킹 5개 뉴스 = 총 60개의 뉴스를 newsData 리스트에 담았습니다.

이제 뉴스의 상세한 글내용과 작성일자, 언론사를 가져오기 위해 뉴스본문 링크로 들어갑니다.
아래는 상위랭킹 1위 뉴스본문 링크입니다.
본문페이지에서 작성일자, 글내용을 가져와봅시다!
https://n.news.naver.com/article/052/0001899591?ntype=RANKING
김기현 "불체포특권 포기 서약하자"...민주 "오로지 남 탓만"
국민의힘 김기현 대표가 교섭단체 대표 연설에서 국회의원 전원의 불체포특권 포기 등 '정치 쇄신 3대 과제'를 여야가 공동 서약하자고 제안했습니다. 더불어민주당 이재명 대표와 지난 문재인
n.news.naver.com
작성일자(입력시간)는 media_end_head_info_datetimestamp_time 클래스에 들어있네요.

가져와줍니다...!
# 뉴스 작성시간
news_time = soup.select_one(".media_end_head_info_datestamp").select_one(".media_end_head_info_datestamp_time").get("data-date-time")
DB에 저장한다면 datetime형으로 변환해서 저장해주면 됩니다.

뉴스 본문 내용은 newsct_article라는 id를 가진 div에 들어있네요. 이것도 가져와줍니다..!!!

참고로 텍스트를 가져온 후 아무 처리도 해주지 않으면 html 태그들이 그대로 수집되게 됩니다. (\n, \t 같은 태그들)
이 태그들을 replace를 통해 제거해주어야합니다!
# 뉴스 본문 내용
news_content = soup.select_one("#newsct_article").text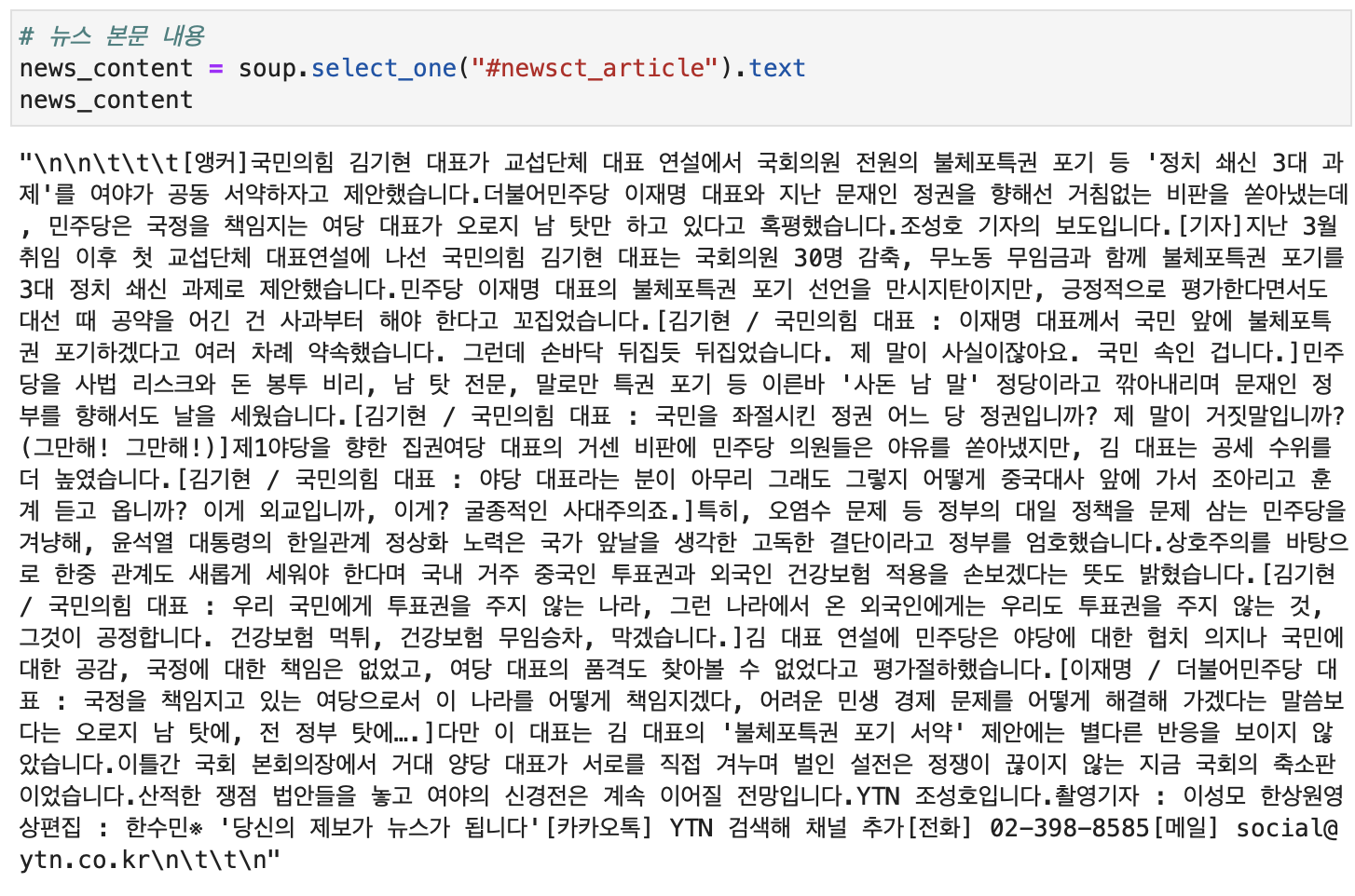
태그 제거 완료!
만약 뉴스게시글을 가지고 분석을 하게 된다면, 기자명이나 전화, 메일 등의 텍스트도 처리를 해주어야 할 것입니다.

이제 newsData 리스트에 들어있는 모든 뉴스의 작성일자와 본문내용을 가져와봅시다!
for news in newsData:
news_url = news['link']
res = requests.get(news_url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
news_time = soup.select_one(".media_end_head_info_datestamp").select_one(".media_end_head_info_datestamp_time").get("data-date-time")
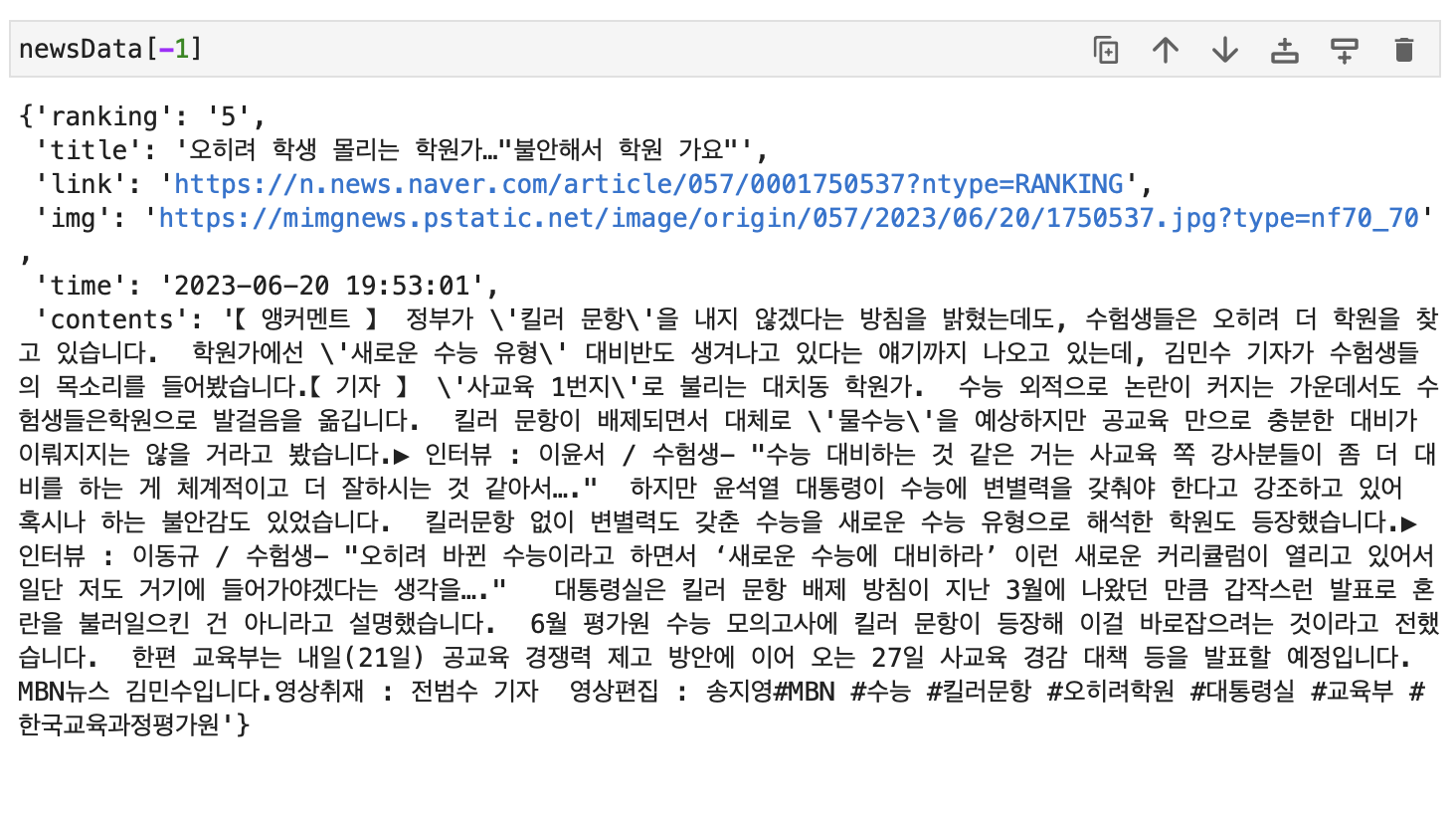
news_content = soup.select_one("#newsct_article").text.replace("\n","").replace("\t","")
news['time'] = news_time
news['contents'] = news_content
제대로 데이터를 긁어온 것을 확인합니다.
판다스 데이터프레임으로 변환하여 확인할 수도 있습니다.
이렇게 댓글많이 달린 랭킹 뉴스 수집하기 완성입니다!

'프로그래밍 > Python' 카테고리의 다른 글
| [mongoDB] 맥북에 몽고DB 설치하는 방법 (1) | 2023.07.14 |
|---|---|
| [pandas] dataframe에 있는 컬럼들을 딕셔너리로 새컬럼 생성하기 (1) | 2023.06.30 |
| [python] xlsx Worksheet index 0 is invalid, 0 worksheets found 오류 (0) | 2023.06.01 |
| [GPT] 한국어버전 GPT, beomi/KoAlpaca-Polyglot 사용해보기 (0) | 2023.05.12 |
| [chatGPT] GPT 3버전 fine-tuning으로 데이터 학습 및 사용 방법 (0) | 2023.03.31 |
