이전 글을 보시려면 아래 링크를 클릭해주세요.
[chatGPT] 파이썬으로 chatGPT API 호출하기
[chatGPT] 파이썬으로 chatGPT API 호출하기
[chatGPT] 파이썬으로 chatGPT API 호출하기 1. 인증키 발급 chatGPT를 API로 호출하기 위해서는 여느 openAPI와 동일하게, 인증키를 발급받아야 합니다. chatGPT API 키를 발급받을 수 있는 openai 페이지로 들어
domdom.tistory.com
fine-tuning은 GPT 모델에 내가 가지고 있는 데이터를 학습시켜, 원하는 형식으로 응답을 받을 수 있도록 모델을 튜닝하는 작업입니다. openai 사이트에 fine-tuning 학습데이터 만드는 방법 등에 대해 자세한 내용이 나와있습니다.
https://platform.openai.com/docs/guides/fine-tuning
OpenAI API
An API for accessing new AI models developed by OpenAI
platform.openai.com
fine-tuning은 다음 프로세스로 진행됩니다.
아주 쉽습니다.
학습 데이터를 준비하여 업로드하고, GPT 모델에 데이터를 학습시키고, 모델을 사용하면 끝!

학습데이터는 다음과 같은 형식으로 만들어져야 하고,
모델은 Davinci, Curie, Babbage, Ada 네 가지 중에 사용할 수 있다고 합니다.
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
이제 학습데이터를 만들어봅시다.
저는 위에서 언급했던 openai fine-tuning 페이지에서 예시 데이터를 가져왔습니다.
{"prompt":"Company: BHFF insurance\nProduct: allround insurance\nAd:One stop shop for all your insurance needs!\nSupported:", "completion":" yes"}
{"prompt":"Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:", "completion":" no"}
터미널에서 데이터파일을 fine-tuning 할 수 있도록 jsonl 형식으로 변경해줍니다.
openai tools fine_tunes.prepare_data -f test.json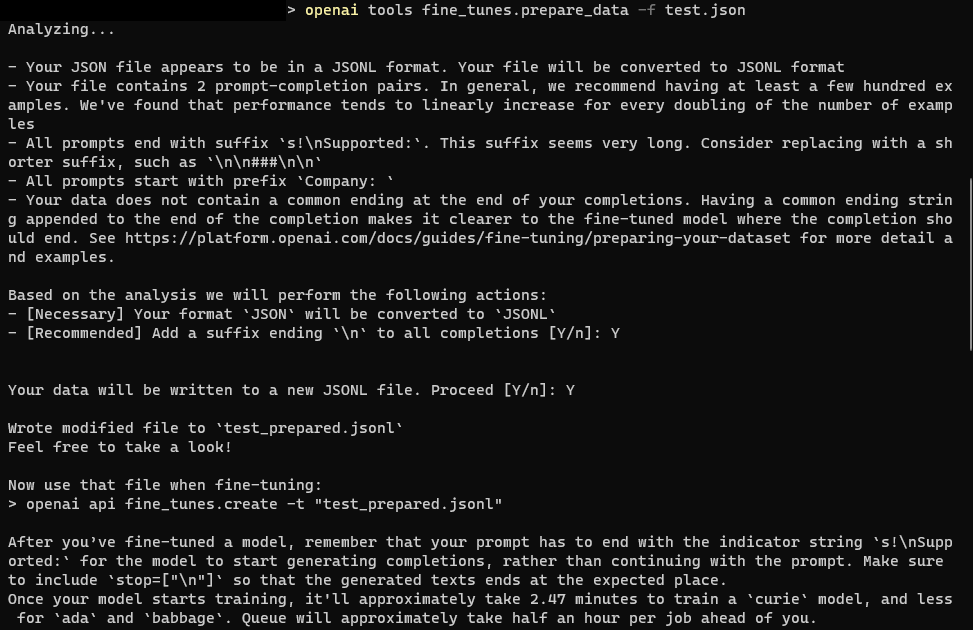
그러면 test.json이 존재하는 동일한 경로에, test_prepared.jsonl 파일이 생성됩니다.
파일을 열어서 비교해보니 별로 달라진 점은 없어보입니다. (예시데이터를 가져왔기 때문..)

test_prepared.jsonl 파일을 학습데이터로 사용하여 모델에 학습시켜봅니다.
명령어는 다음과 같습니다.

저는 인증키를 환경변수에 추가하지 않았으므로 명령어에 --api-key를 넣어서 명령어를 작성했습니다.
명령어를 넣지 않으면 아래와 같은 에러가 발생하게 됩니다.
Error: No API key provided.

저는 davinci 모델을 사용해서 진행했습니다.
openai --api-key {인증키} api fine_tunes.create -t test_prepared.jsonl -m davinci
명령어를 실행시키면 Upload progress는 정상적으로 진행이 되구요.
업로드 중에 Stream interrupted (client disconnected). 라는 에러가 종종 리턴됩니다.
이는 우리문제가 아니라 openai 서버쪽 문제라 (사용하는 사람이 워낙 많으니...) 계속 시도해야합니다.
구글링해보면 openai를 0.25.0 버전(?)으로 다운그레이드하면 잘된다는 말도 있더군요,,

처음부터 다시 시작하지 않고, 모델학습을 진행을 계속 이어나가게끔 시도할 수 있는 명령어가 있습니다.
위에 에러에서 맨 마지막 줄에 나오는 openai api fine_tunes.follow -i 다음에 있는 fine-tune 작업ID를 복사해주세요.
저의 경우 ft-PLYtbBLfcGg1DTFcGv9IT9Nx가 작업 ID 이네요.

다시 재시도 해봤더니 이번에는 Fine-tune 진행하는데 소요되는 costs ($0.01)와, Queue number가 나옵니다.
사용하는 사람이 많으면 이 Queue 안에 대기줄이 엄청많으므로... 계속해서 Stream interrupted (client disconnected). 오류가 나게됩니다. 오류가 또 났으니 계속해서 이 명령어를 반복입력해줍니다.
openai --api-key {인증키} api fine_tunes.follow -i ft-PLYtbBLfcGg1DTFcGv9IT9Nx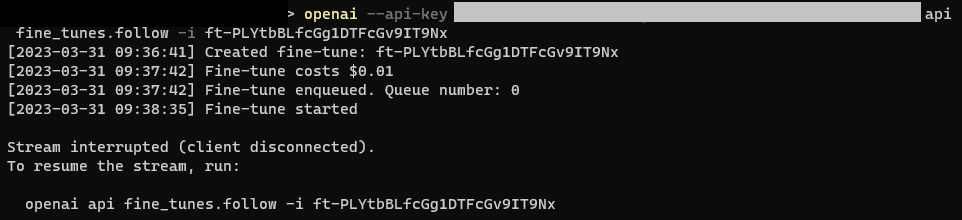
제대로 학습이 완료되면 아래와 같이 epoch 진행상황과 Fine-tune succeeded를 확인할 수 있습니다.
제가 fine-tuning한 모델명은 davinci:ft-personal-2023-03-31-00-41-40 이네요.

이제 학습한 모델을 사용해봅시다.
prompt에는 학습할 때 넣었던 내용을 그대로 넣어봤습니다.
import openai
openai.api_key = '{인증키}'
completion = openai.Completion.create(
model="davinci:ft-personal-2023-03-31-00-41-40",
prompt="Company: Loft conversion specialists\nProduct: -\nAd:Straight teeth in weeks!\nSupported:",
max_tokens=30,
temperature=0,
)
print(completion['choices'][0]['text'])
대답이 정상적으로 나오는 것을 확인합니다.
max_tokens을 조절하여 원하는 대답의 길이를 설정할 수 있습니다.
한국어로도 해봤는데 한국어는 이상한 대답을 주더라고요. 좀 더 업그레이드 된 버전이 나오기를 기다려야할 것 같습니다.

[GPT] 한국어버전 GPT, beomi/KoAlpaca-Polyglot 사용해보기
[GPT] 한국어버전 GPT, beomi/KoAlpaca-Polyglot 사용해보기
chatGPT 데이터 학습 및 사용 방법은 아래 링크를 눌러주세요! [chatGPT] GPT 3버전 fine-tuning으로 데이터 학습 및 사용 방법 [chatGPT] GPT 3버전 fine-tuning으로 데이터 학습 및 사용 방법 이전 글을 보시려면
domdom.tistory.com
'Dev > Python' 카테고리의 다른 글
| [python] xlsx Worksheet index 0 is invalid, 0 worksheets found 오류 (0) | 2023.06.01 |
|---|---|
| [GPT] 한국어버전 GPT, beomi/KoAlpaca-Polyglot 사용해보기 (0) | 2023.05.12 |
| [geopandas] 파이썬에서 shp형식의 파일을 geojson 파일로 변환하기 (0) | 2023.03.30 |
| [chatGPT] 파이썬으로 chatGPT API 호출하기 (1) | 2023.03.27 |
| [geopandas] 윈도우에서 파이썬 GeoPandas 에러없이 설치하기 (0) | 2023.03.11 |
Comments