🩷 방문자 추이
🏆 인기글 순위
티스토리 뷰
[python] xlsx Worksheet index 0 is invalid, 0 worksheets found 오류
돔돔이 2023. 6. 1. 00:00
"https://url.xlsx" 이런 xlsx 파일 링크를 requests.get을 통해 파일을 다운로드했는데 에러가 날 때가 있더라고요.
(원래는 아래 코드로 정상적으로 다운로드 되어야 함)
file = pd.read_excel(io.BytesIO(requests.get(download).content), engine="openpyxl")
# 에러문구
openpyxl\reader\workbook.py:84: UserWarning: File contains an invalid specification for 0. This will be removed
warn(msg)ValueError: Worksheet index 0 is invalid, 0 worksheets found
실제로 링크에 들어가서 파일을 다운로드받고, 엑셀로 열어봤을 때는 정상적으로 열리지만
파이썬으로 다운받아 판다스로 열어보려고 할때는 에러가 납니다.
무슨 이유때문에 에러가 나는지 확인해보니,
파일형식이 기본 xlsx파일이 아닌, Strict Open XML 스프레드시트 일 때 에러가 나더라고요.
다운로드 받은 파일을 열어 파일형식을 확인해보았습니다.

XML로 만들어진 xlsx 파일 인 듯 합니다.
기존과 동일한 방식으로는 다운로드 받을 수 없을 듯 하여,
XML로 만들어졌으니, XML 방식으로 파싱해오도록 하는 방법을 사용했습니다.
아래 사이트를 참고했습니다.
사이트에는 아래와 같이 xlsx 파일을 xml 파일로 변환하여 저장하는 코드가 있습니다.
https://products.aspose.com/cells/ko/python-java/conversion/xlsx-to-xml/
XLSX을 XML Python via Python로 변환
무료로 XLSX을 XML 온라인으로 변환합니다. 무료 온라인 XLSX을 XML로 변환합니다. Python XLSX을 XML로 변환합니다. XLSX을 Python을 통해 XML로 변환합니다.
products.aspose.com
import jpype
import asposecells
jpype.startJVM()
from asposecells.api import Workbook
workbook = Workbook("input.xlsx")
workbook.save("Output.xml")
jpype.shutdownJVM()
저는 url을 통해 xlsx 파일을 가져와야 하므로, 일단 파일을 xlsx 형식으로 저장했습니다.
import requests
resp = requests.get(url)
output = open('input.xlsx', 'wb')
output.write(resp.content)
output.close()
이제 위 코드를 활용하여 "Output.xml" 파일을 새로 생성할 수 있습니다.
파일이 정상적으로 저장된 것을 확인합니다.

저장한 xml파일은 ElementTree로 파싱하여 데이터를 가져오면 됩니다.
from xml.etree.ElementTree import parse
tree = parse('Output.xml')
root = tree.getroot()
root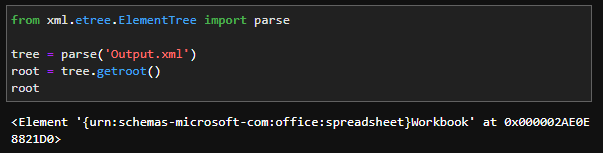
그 다음 부터는 원하는 데이터를 파싱하면 끝입니다!
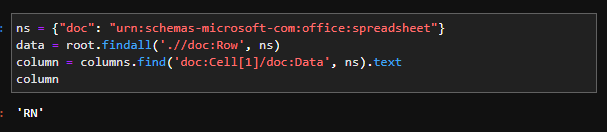
ns = {"doc": "urn:schemas-microsoft-com:office:spreadsheet"}
data = root.findall('.//doc:Row', ns)
column = columns.find('doc:Cell[1]/doc:Data', ns).text
...
'프로그래밍 > Python' 카테고리의 다른 글
| [pandas] dataframe에 있는 컬럼들을 딕셔너리로 새컬럼 생성하기 (1) | 2023.06.30 |
|---|---|
| [크롤링] 파이썬으로 네이버 뉴스 크롤링하기 (0) | 2023.06.20 |
| [GPT] 한국어버전 GPT, beomi/KoAlpaca-Polyglot 사용해보기 (0) | 2023.05.12 |
| [chatGPT] GPT 3버전 fine-tuning으로 데이터 학습 및 사용 방법 (0) | 2023.03.31 |
| [geopandas] 파이썬에서 shp형식의 파일을 geojson 파일로 변환하기 (0) | 2023.03.30 |
