
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Domdomi</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content">Hello World</p>
</div>
</div>
</body>
</html>우선 HTML부터 얘기해보면 HTML은 요소(Element)와 속성(Attribute)으로 이루어져 있습니다. 그리고 요소와 요소, 요소와 속성 간에 계층 관계가 있음을 알 수 있습니다.
만약에 title 클래스의 자식 요소인 p 태그의 내용을 가지고 오고 싶다면 어떨까요? 위 코드에서는 정말 순식간에 알아챌 수 있겠죠. (selector 표현식으로 표현하면 이렇겠죠. body > div#container > div.title > p)
하지만 아주 복잡하게 구현되어 있는 네이버나 다음 같은 웹 페이지에서 바로 내가 원하는 부분을 절대 경로로 가져오는 것은 매우 길고 복잡한 경로(path)가 필요하게 될 것입니다. 이러한 문제를 해결하기 위해서 나온 개념이 XPath(XML Path Language)로 내가 원하는 요소 또는 속성을 찾기 위한 질의어라고 할 수 있습니다.
XPath(XML Path Language)는 W3C의 표준으로 확장 생성 언어 문서의 구조를 통해 경로 위에 지정한 구문을 사용하여 항목을 배치하고 처리하는 방법을 기술하는 언어이다.
- 위키백과 -
XPath는 다양한 언어에서 사용될 수 있습니다. 기본적으로 XML이나 XSLT에서 사용될 수 있고, Java, Javascript, Python, PHP, C/C++ 등등 많은 언어에서 사용되고 있다고 합니다.
XPath 문법
기본적으로 특정 요소나 속성을 찾고 싶을 때 다음과 같은 문법을 사용하여 접근할 수 있습니다.
| / | 현재 위치의 자식 노드만 검색 | ex) /html/div/div/p |
| // | 현재 위치의 모든 자손 노드에서 검색 | ex) //p |
| * | 경로에 있는 모든 노드를 반환 | ex) /html/div/div/* |
| [ ] | 필터 표현식으로 인덱스, 속성 등을 통해 특정 요소를 검색 | |
| [index] | 검색된 노드들 중 index에 해당하는 노드 반환, 1부터 시작 | ex) //p[1] |
| [@attr] | 검색된 노드들 중 해당 속성을 가지고 있는 모든 노드를 반환 | ex) //p[@class] |
| [@attr="value"] | 검색된 노드들 중 해당 속성과 속성 값이 일치하는 노드를 모두 반환 | ex) //p[@class="content"] |
사실 위의 예시들 외에도 위치 경로(location path) 표현식, 검색방향(axis step) 설정, 경로 표현식(path expression), 필터 표현식(filter expression), XPath 함수(XPath Functions), 와일드카드(Wildcards), 연산자(Operator) 등의 다양한 문법들이 존재합니다만, 여기서는 웹 스크래핑/크롤링 할 때 자주 보일 수 있는 기본적인 부분만 언급하고 넘어가도록 하겠습니다.
그리고 실제로 위에 언급한 모든 문법을 익힐 필요가 없는 것이 브라우저에서 우리가 원하는 부분의 XPath를 자동으로 추출해주기 때문에 기본 문법만 눈에 익히기만 한다면 문제가 없을 것이라고 생각됩니다.
혹시 다양한 XPath 사용법을 더 눈에 익히고 싶으시다면 아래 사이트에 들어가셔서 보시기를 추천드립니다. 아래 사이트에서는 다양한 사람들이 자주 사용하게 되는 XPath 표현식을 한번에 정리 해놓은 사이트이기도 합니다.
Xpath cheatsheet
$x('//div//p//*') == $('div p *'), $x('//[@id="item"]') == $('#item'), and many other Xpath examples. · One-page guide to Xpath
devhints.io
웹브라우저에서 XPath 찾는 방법
실제로 웹브라우저에서 내가 웹 스크래핑/크롤링 하고 싶은 부분의 XPath를 찾는 방법은 클릭 몇번으로 할 수 있을 정도로 매우 쉽습니다.

실제 구글에서 돔돔이블로그를 검색해보았습니다. 그리고 위 이미지에서 제목 부분의 XPath를 가져와 보겠습니다.
우선 브라우저에서 개발자도구(F12)를 실행해주세요.

그럼 위와 같은 창이 나오는데 여기서 좌측 상단의 마우스 표시를 눌러주세요. 그리고 마우스를 가져오기 원하는 부분에 가져다대면 아래와 같이 나옵니다.
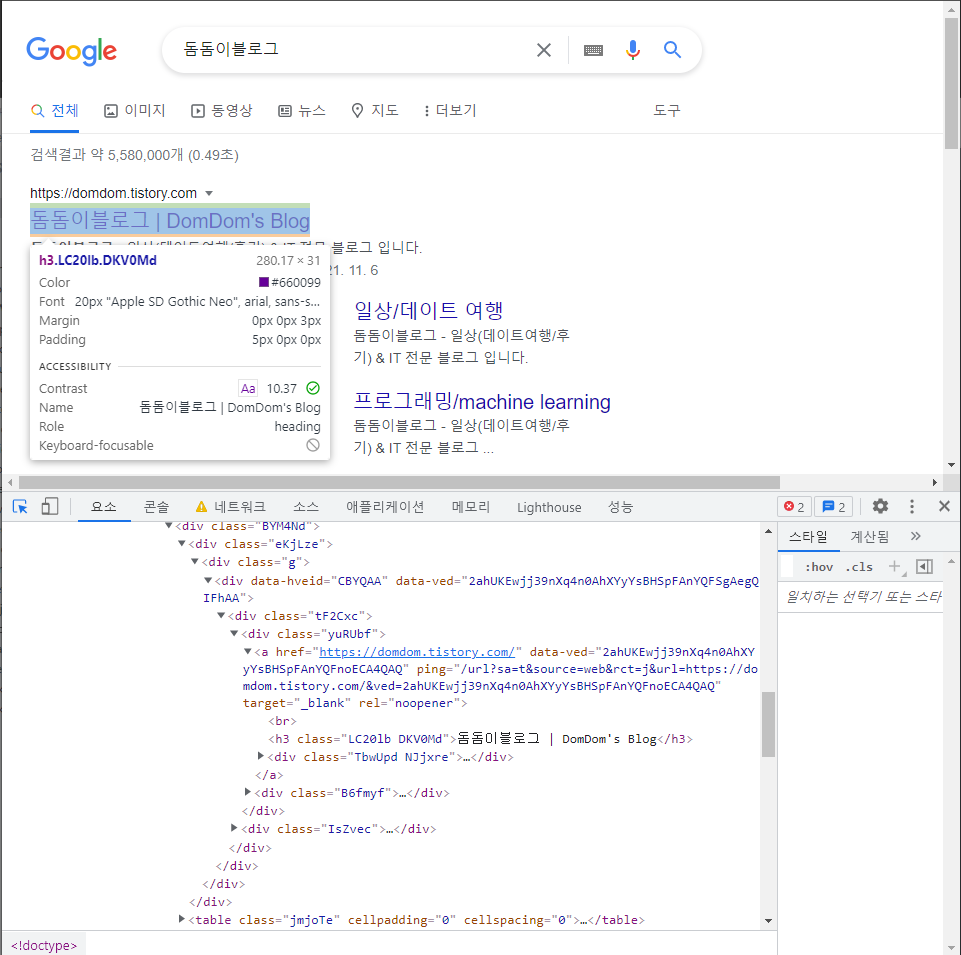
이제 마우스를 가져다댄 곳을 클릭하게 되면 아래와 같이 개발자도구에서 실제 HTML 코드에 원하는 부분의 태그를 보여줍니다.
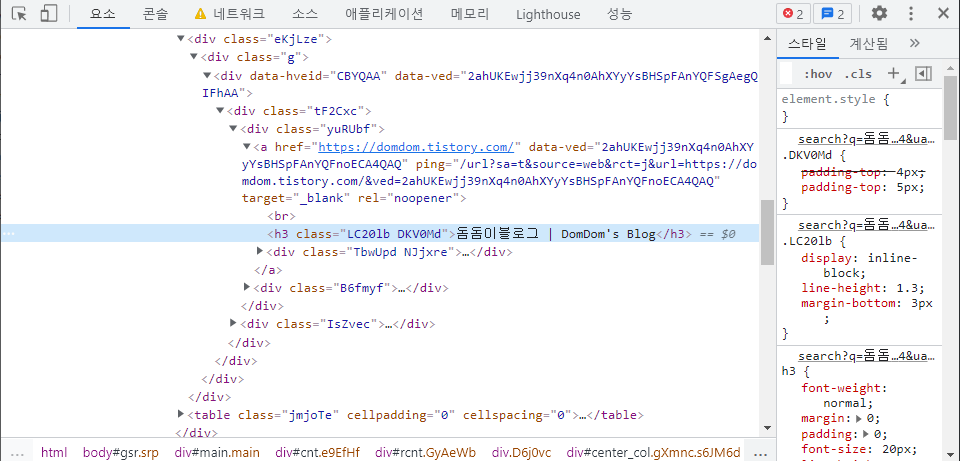
이제 여기서 파란색으로 돔돔이블로그의 제목 부분을 표시하고 있는 부분에 마우스를 가져다 댄 다음에 우측 클릭을 하면 아래와 같이 나옵니다.

영어로는 Copy -> Copy XPath 라고 되어 있을 겁니다. 이제 위 화면에서 XPath 복사 버튼을 누르게 됩니다. 이제 복사한 내용을 붙여넣기 해보면 아래와 같이 나올 겁니다.
//*[@id="rso"]/div[1]/div/div/div/div/div/div[1]/a/h3
그리고 추가로 위 XPath를 역으로 HTML코드에서 찾고 싶다면 아래와 같이 할 수 있습니다.

개발자도구(F12)에서 콘솔(Console) 탭에서 방금 전의 XPath를 복사하고 $x() 함수를 사용하여 javascript 명령을 실행하게 되면 해당 XPath 부분이 HTML 상에서 어떤 위치인지를 바로 알려주게 됩니다.
$x('//*[@id="rso"]/div[1]/div/div/div/div/div/div[1]/a/h3')[0]
이렇게 XPath에 대해서 간단히 기본 개념만 익혀보았고, 이제부터 웹 스크래핑/크롤링에서는 XPath가 어떻게 활용될 수 있는지에 대해 더 공부해볼 예정입니다.
'Dev > Python' 카테고리의 다른 글
| [크롤링] Python에서 웹 크롤러 만들 때의 정규식 사용 (2) | 2021.11.09 |
|---|---|
| [크롤링] Python의 requests 모듈 기본 사용법 (0) | 2021.11.09 |
| [Python] 특정 자료형의 내장함수 찾는 방법 - dir() 함수 (0) | 2021.11.07 |
| [Python] 모듈(module) 위치 찾는 법 - inspect (0) | 2021.11.07 |
| [Python] Exception 클래스 그리고 예외처리(try, except, raise, finally) (0) | 2021.11.07 |
Comments