티스토리 뷰
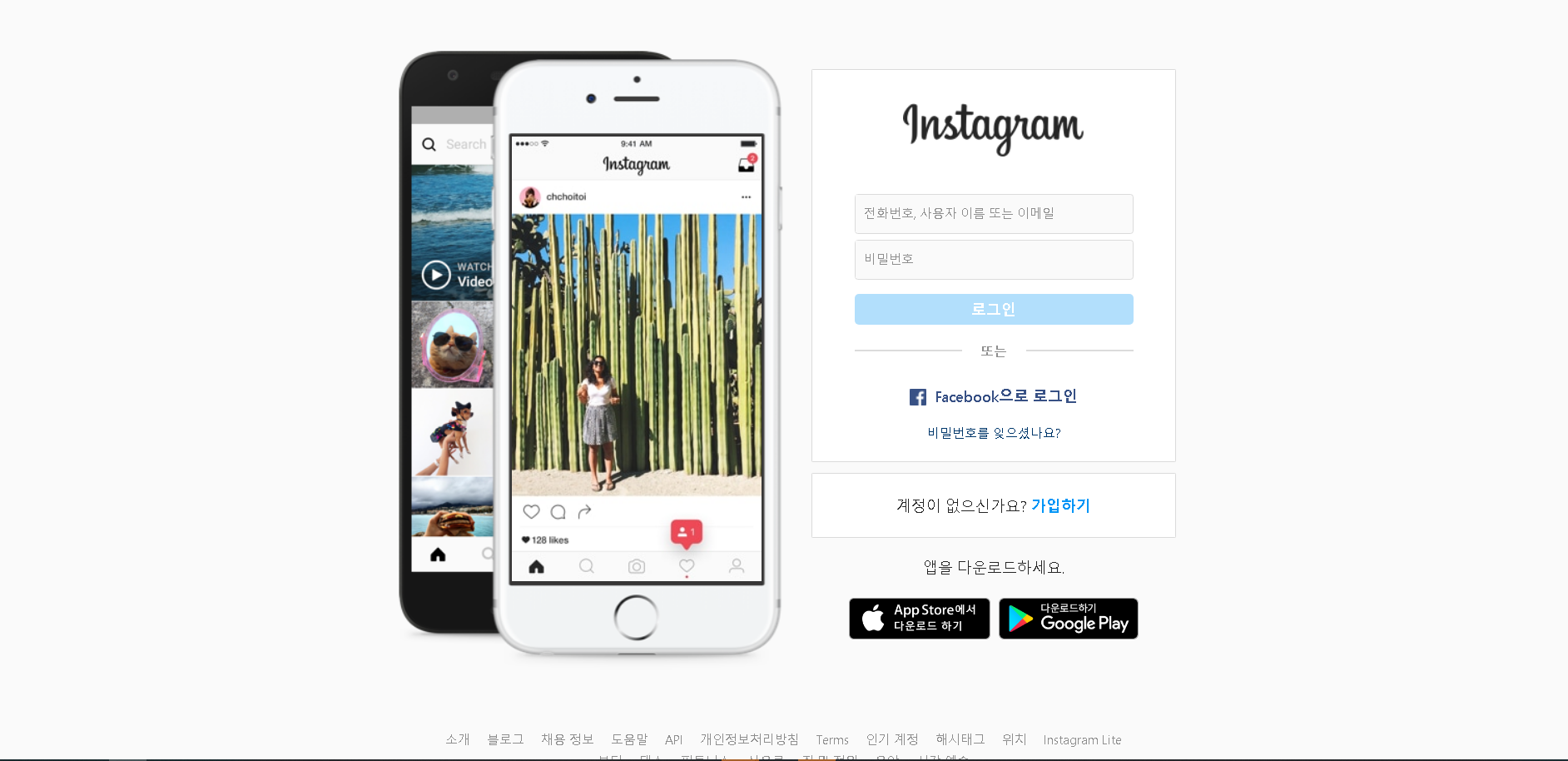
처음 인스타그램 사이트에 들어가면 로그인창이 나와요.
일단 로그인을 해줍니다!
그리고서,
원하는 게시물을 크롤링 하기 위해 게시물을 검색해볼게요.
저는 강아지를 좋아하기 때문에 "댕댕이"를 검색해봤어요.
"댕댕이"가 해시태그로 들어간 게시물이 13,774,470건이나 있네요!
이 게시물들을 크롤링해볼거에요.
원하는 해시태그가 들어간 게시물 크롤링이랍니다!
천만개가 넘어갈만큼 게시물이 굉장히 많이 때문에 셀레니움을 쓰면 시간이 엄청많이 걸릴거에요..
우리는 파이썬의 requests 모듈을 통해 json형태로 게시물을 받아올겁니다!

인스타그램 게시물을 json형태로 게시물을 뿌려주는 아주 착하고 유명한(?) 페이지가 있어요.
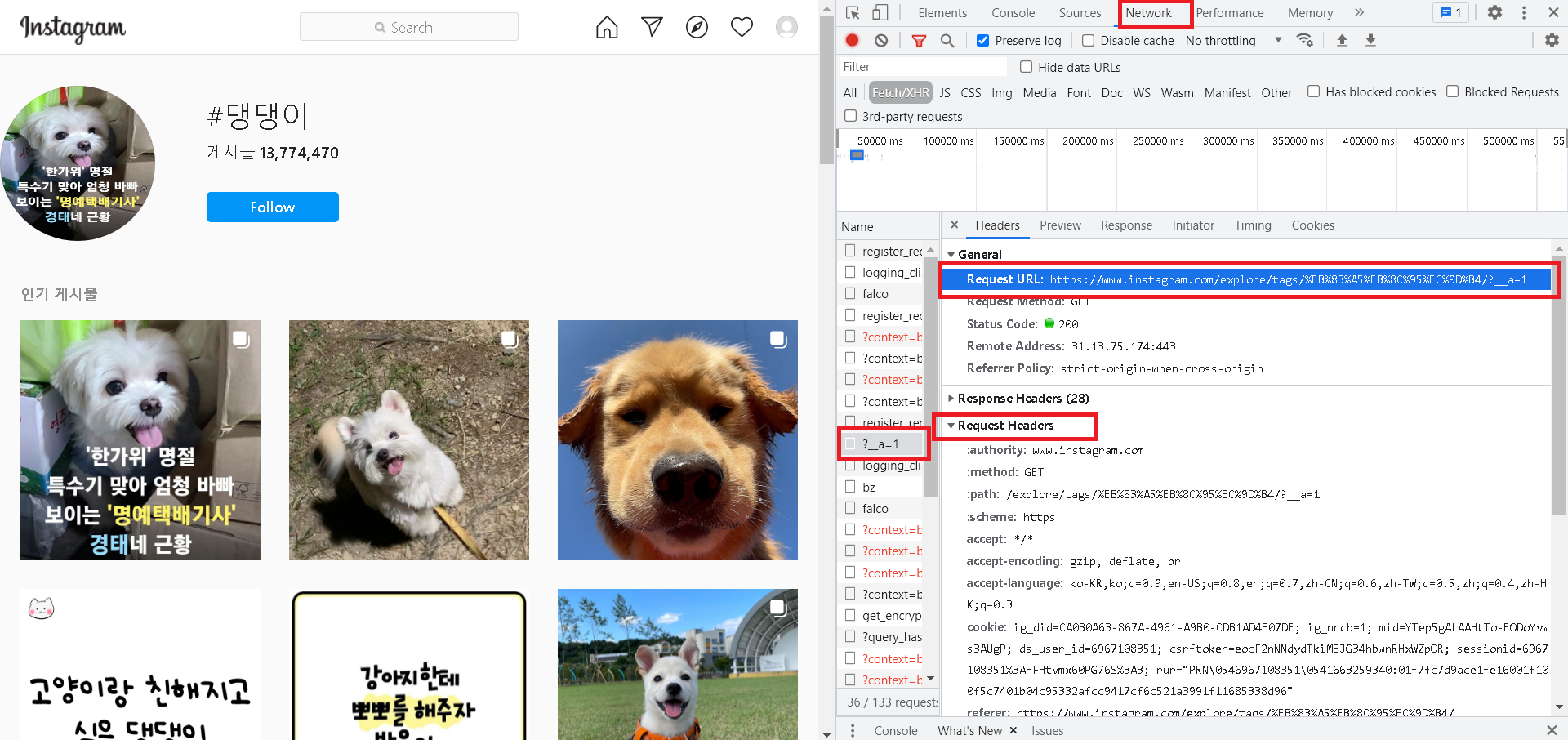
키워드를 검색하기 전에 개발자도구를 열어서 (F12)
Network 탭을 들어간 후,
키워드를 검색하면 네트워크에 나온 것들 중에 ?__a=1이라는 Name이 있습니다!
전체 URL은 아래와 같이 생겼어요.
https://www.instagram.com/explore/tags/%EB%8C%95%EB%8C%95%EC%9D%B4/?__a=1
위 URL은 https://www.instagram.com/explore/tags/댕댕이/?__a=1 와 같답니다.
검색URL 뒤에 ?__a=1만 붙여주면, json으로 출력해주네요.
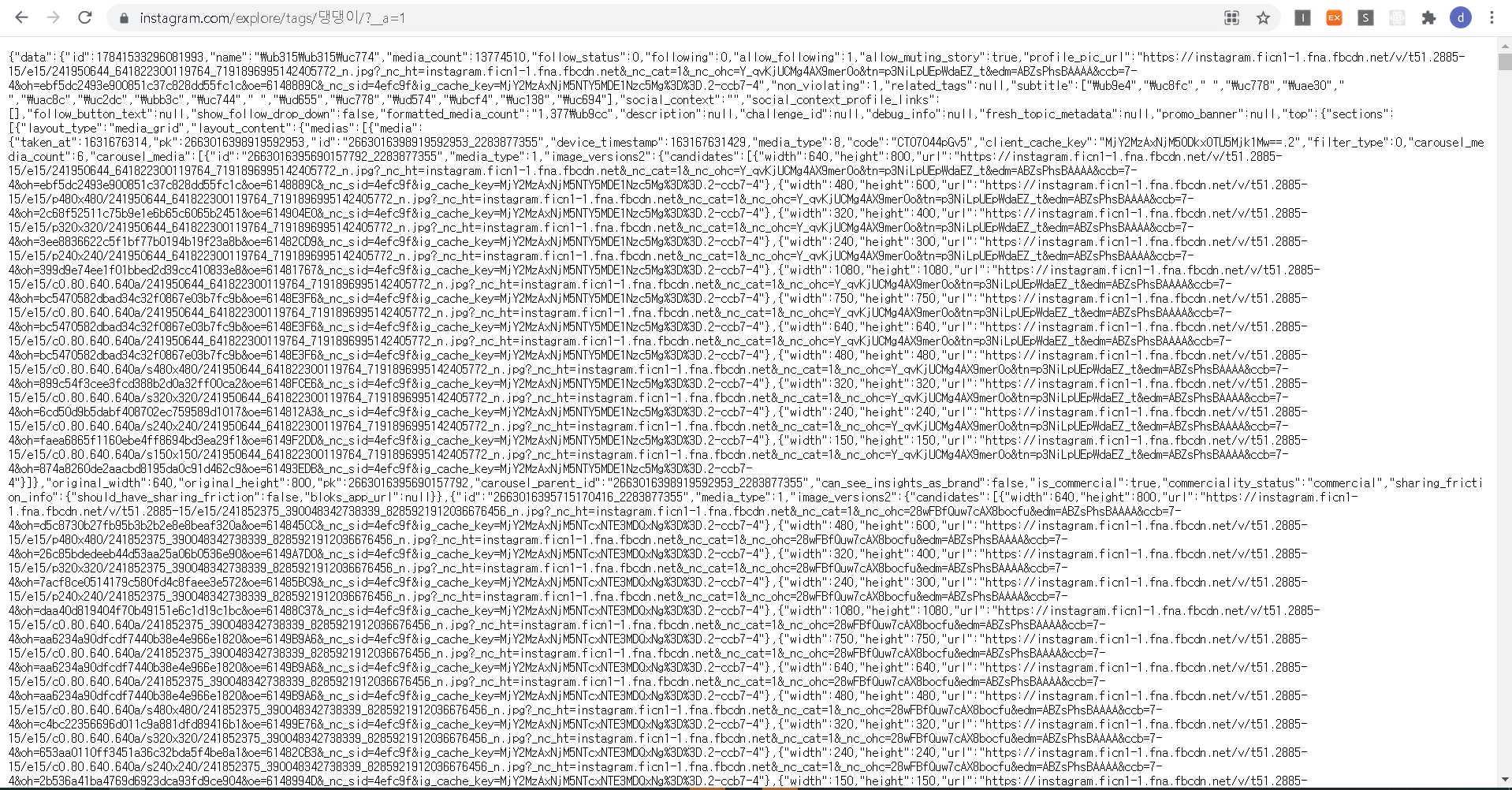
실제로 이 URL을 복사해서 들어가니
댕댕이에 관한 게시물이 JSON으로 출력되고 있음을 확인할 수 있었어요.
하지만 이것은 몇 십개의 게시물에 불과하고, 계속해서 다음 게시물을 가져오려면
리퀘스트 헤더와 다음페이지의 ID가 필요합니다.
따라서, 먼저 아까 네트워크에 있던 Request Headers를 복사해옵니다!
짠
이렇게 헤더를 딕셔너리 형태로 가져왔어요.
(이 세션값은 계속해서 변경되므로 주의하세요)
header = {
'accept': '*/*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': '쿠키값',
'referer': 'https://www.instagram.com/explore/tags/nike/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-asbd-id': '437806',
'x-ig-app-id': '936619743392459',
'x-ig-www-claim': 'hmac.AR3PaP-bDTR_oeoJDshsARVmCSEaxtvdlgmeEkWuH2ti5SwH',
'x-requested-with': 'XMLHttpRequest'
}
그다음 검색URL과 함께 헤더를 넣고 requests.get으로 json 데이터를 가져옵니다
URL = 'https://www.instagram.com/explore/tags/댕댕이/?__a=1'
res = requests.get(URL, headers =header)
res = res.json()
가져온 결과값을 확인해보니
아까 봤던 페이지의 json 데이터들이 그대로 가져와졌음을 알 수 있어요.
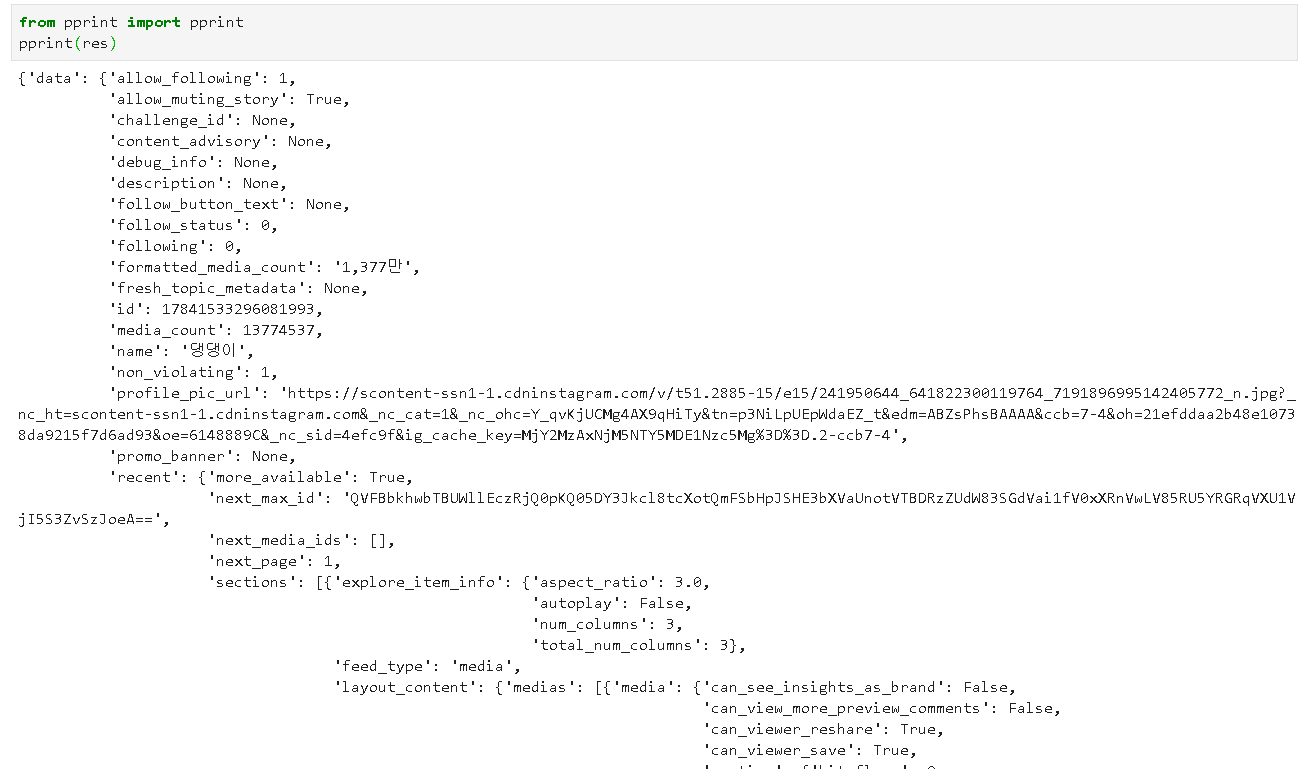
가져온 json 데이터의 키를 확인해보니 'data' 하나가 있고,
data의 키들을 확인해보니 엄청 많은 키들이 있어요.

media_count는 댕댕이 태그가 들어간 총 게시물 수이고,
profile_pic_url은 댕댕이 태그를 검색했을 때 나온 프로필 이미지네요.
가장 중요한 키는 top 과 recent인데요,
top은 인기게시물, recent는 최근게시물이 들어있습니다!
최근게시물은 최근에 게시된 게시물부터 이전에 게시된 게시물까지 정렬되어있으므로
저는 최근게시물인 recent를 가져오도록 할게요.

recent의 키들을 보니 next_page, next_max_id가 있어요!
next_page가 1이면 다음페이지가 있다는 의미에요.
next_max_id는 다음페이지를 열기 위한 id입니다.
sections에는 게시물 데이터들이 들어있어요.
sections의 타입은 리스트입니다.
이런식으로 처음에는 어느 키에 어떤 값들이 들어가있는지 확인해보는 것이 좋아요.

이제 sections에 있는 게시물 데이터들을 가져와볼게요.
데이터를 담을 빈 리스트 dataList를 하나 초기화해두고요,
게시물 데이터가 담겨져 있는 res['data']['recent']['sections']를 돌면서 하나하나 리스트에 담아줍니다.
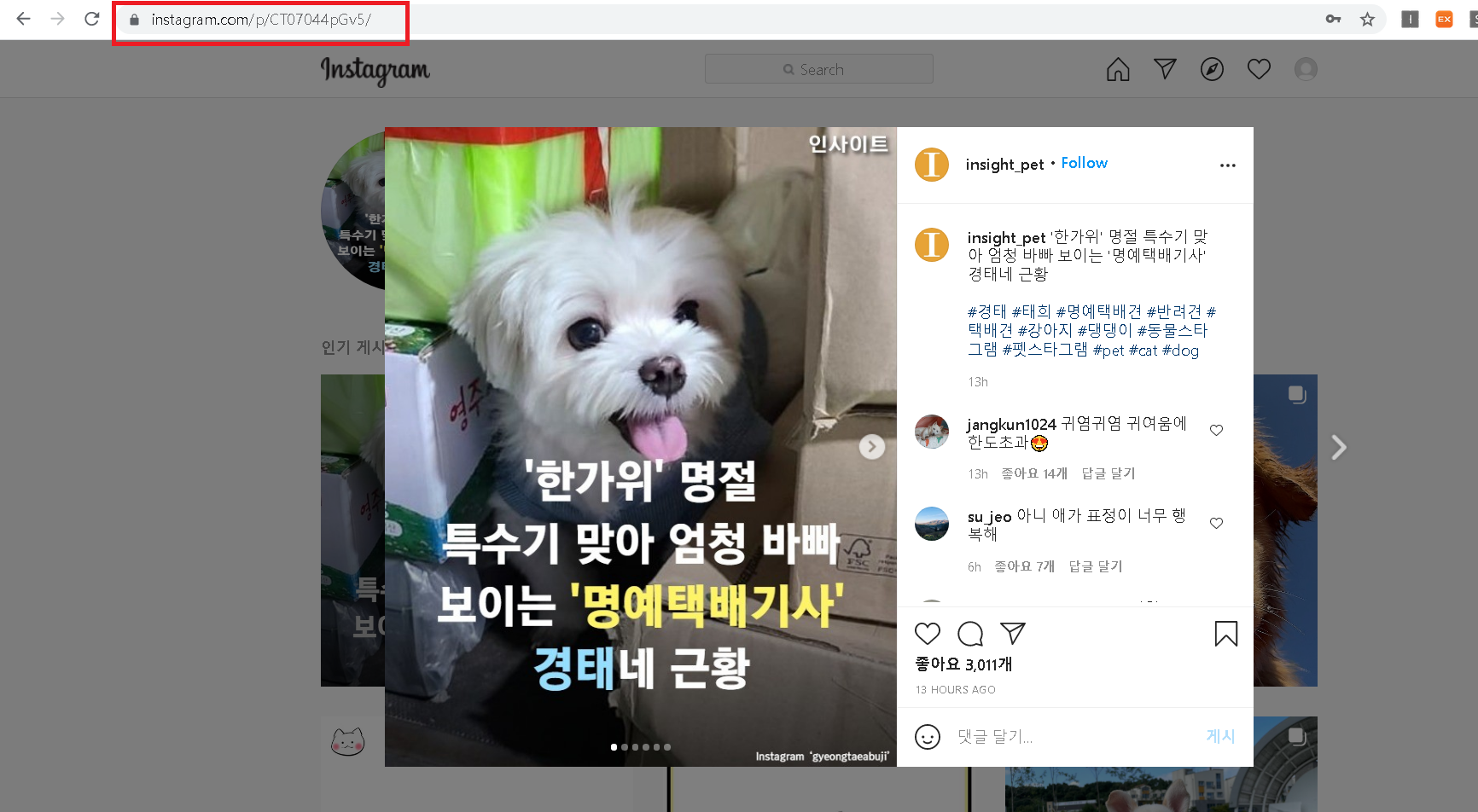
sections의 medias키 안에 'code'가 있는데, 게시물마다 pk id인 code를 의미해요.
예를 들어 아래 게시물같은 경우 code는 'CT07044pGv5'가 됩니다.
URL에서 이 code만 게시물마다 변경해주면 해당 게시물을 조회할 수 있게 되죠.
따라서 code를 가져오면 게시물의 URL을 알 수 있어요.
'instagram.com/p/' + code + '/'
게시물 작성일자는 타임스탬프 형식으로 되어있어서, datetime.fromtimestamp를 통해 알아보기 쉽게 변경했습니다.
그리고 게시물의 좋아요 수, 작성자 닉네임, 작성자 pk, 작성자이름, 작성자 프로필을 가져올 수 있어요.
게시물 썸네일 이미지 URL도 가져올 수 있는데 저는 필요없어서 가져오지 않았습니다.
저는 가져올 데이터만 추려서 가져왔고,
이외에도 가져올 수 있는 데이터가 많이 있으니 한번 모든 키를 확인해보세요!
그리고, 에러사항이 있다면, 댓글은 미리보기라서 최대 2개까지 밖에 안가져와져요.
dataList = []
for n in res['data']['recent']['sections']:
for m in ((n['layout_content']['medias'])):
m = m['media']
data = {}
data['keyword'] = '댕댕이'
data['pagePk'] = m['code']
data['URL'] = 'https://www.instagram.com/p/'+ data['pagePk']+"/"
try: data['DatePublished'] = datetime.fromtimestamp(m['caption']['created_at'])
except: continue
data['Content'] = delrn(m['caption']['text'])
try:
data['reply'] = (m['comment_count'])
data['replyList'] = (m['comments'])
except:
data['reply'] = 0
data['replyList'] = []
data['like'] = (m['like_count'])
data['pk'] = str(m['pk'])
data['user_full_name'] = (m['user']['full_name'])
data['user_pk'] = str(m['user']['pk'])
data['user_name'] = (m['user']['username'])
data['user_profile'] = (m['user']['profile_pic_url'])
dataList.append(data)
이제 데이터를 담은 dataList를 출력해보면,
게시물 데이터들이 딕셔너리형태로 dataList 리스트에 잘 담겨져 있는 것을 확인할 수 있어요.

그리고 이 페이지가 모든 게시물을 담고 있지는 않기 때문에,
이 페이지의 모든 게시물을 가지고 왔따면 다음페이지로 넘어가서 또 크롤링을 해옵니다!
다음 페이지로 넘어가기 위해서는 아까 recent에서 봤던 res['data']['recent']['next_max_id']를 URL에 추가해주면 돼요.
이번 페이지도 전 페이지처럼 똑같이 리스트에 담고,
또 똑같이 res['data']['recent']['next_max_id']를 통해 다음 페이지로 넘어갈 수 있답니다.
다음 페이지로 갈수록 이전에 작성된 게시물이 나와요.
따라서 가장 최근의 글부터, 원하는 날짜까지의 게시물을 수집할 수 있죠!

다음페이지가 없을 때까지(마지막페이지까지) 가져오려면 아래와 같이
while문을 통해 계속해서 다음페이지로 넘어가면 됩니다!
하지만 너무 봇처럼 하루죙일 크롤링을 돌린다거나 하면,
계정이 해킹을 당한것같다며 비밀번호를 변경하라고 뜨면서 헤더값이 먹히지 않으니 유의하세요!
dataList = []
URL = 'https://www.instagram.com/explore/tags/댕댕이/?__a=1'
while(True):
res = requests.get(URL, headers =header)
res = res.json()
if 'next_page' not in res['data']['recent'].keys() or int(res['data']['recent']['next_page']) == 0: break
max_id = res['data']['recent']['next_max_id']
for n in res['data']['recent']['sections']:
for m in ((n['layout_content']['medias'])):
m = m['media']
data = {}
data['keyword'] = keyword
data['pagePk'] = m['code']
data['URL'] = 'https://www.instagram.com/p/'+ data['pagePk']+"/"
try: data['DatePublished'] = datetime.fromtimestamp(m['caption']['created_at'])
except: continue
data['Content'] = delrn(m['caption']['text'])
try:
data['reply'] = (m['comment_count'])
data['replyList'] = (m['comments'])
except:
data['reply'] = 0
data['replyList'] = []
data['like'] = (m['like_count'])
data['pk'] = str(m['pk'])
data['user_full_name'] = (m['user']['full_name'])
data['user_pk'] = str(m['user']['pk'])
data['user_name'] = (m['user']['username'])
data['user_profile'] = (m['user']['profile_pic_url'])
dataList.append(data)
URL = 'https://www.instagram.com/explore/tags/'+keyword+'/?__a=1&max_id='+max_id
끝입니다!
'프로그래밍 > Python' 카테고리의 다른 글
| [Dictionary] 딕셔너리에서 list of key 들이 존재하는 지 확인하는 법 (0) | 2021.09.17 |
|---|---|
| [영어인가 한국어인가?] 파이썬으로 문장이 영어인지 한국어인지 구분하기 (0) | 2021.09.16 |
| [오류해결] Python BeautifulSoup - MarkupResemblesLocatorWarning (0) | 2021.09.15 |
| [Python2.7] Python2에서 pip 설치 방법 (0) | 2021.09.13 |
| [Python3] 리눅스/Windows에서 python gmpy, gmpy2 설치 방법 (0) | 2021.09.13 |
