티스토리 뷰

네이버와 다음 모두, 실시간 검색어가 폐지된 것을 아시나요?
왜 폐지된지 찾아보니, 과도한 마케팅과 여론 조작 논란 때문이라고 하네요.
이전에 네이버 실시간 검색어 크롤링에 대해서 블로그에 작성해두었었는데, 무용지물이 되어버렸어요ㅜㅜ
네이버와 다음은 실시간 검색어가 폐지되었지만, 아직 네이트에는 실시간 검색어가 있어서 네이트 실시간 검색어를 가져와보려고 합니다!
원래는 인기검색어만 가져오려고 했었는데, 크롤링을 하다보니 실시간 이슈키워드 까지 가져오게 되었어요.
[네이트 인기 검색어와 실시간 이슈 키워드 크롤링]
한눈에 보는 오늘 : 네이트
새로워진 nate에서 당신의 오늘을 만나보세요
www.nate.com
네이트 메인페이지에 들어가면 오른쪽 상단에 Biz. 인기 검색어가 존재합니다.
인기 검색어들의 소스를 가져오기 위해 개발자도구(F12 또는 Ctrl+Shift+i)를 열어 개발자도구의 왼쪽상단에 있는 마우스버튼을 클릭한 뒤, 사이트의 Biz. 인기 검색어를 누르면 바로 인기검색어의 소스를 확인할 수 있어요.

인기검색어는 bizRank라는 id의 div안에 들어있네요 ! 딱보면, h3태그 Biz. 인기 검색어 아래에 있는 ol > li 들이 순위별 인기검색어들인 것 같죠? 가져오도록 하겠습니다.
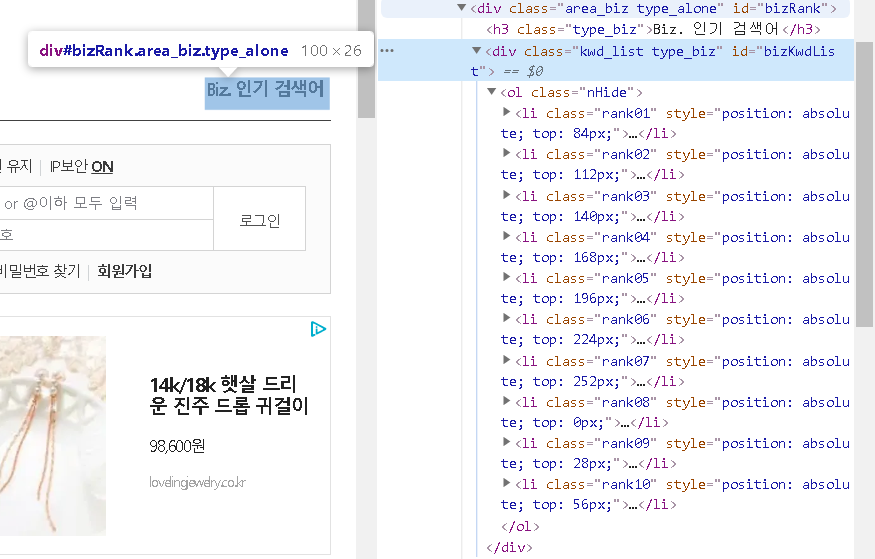
아래와 같이 bizRank라는 id의 div 태그를 가져와 출력해보면 비즈 검색어 아래 순위별 검색어들이 있어야하는데, h3태그까지만 출력되는 것을 확인할 수 있어요.
|
1
2
3
4
5
6
7
8
9
10
11
|
import requests
import json
from bs4 import BeautifulSoup as bs
#네이트 사이트 링크
url = 'https://www.nate.com/'
req = requests.get(url)
soup = bs(req.text, 'lxml')
bizRank = soup.find("div",{"id":"bizRank"})
bizRank
|

이렇게 가져온 html소스에 데이터가 존재하지 않으면, 다른 페이지에서 해당 데이터(실시간 순위 검색어들)를 API처럼 쏴주고 있다는 것을 의미합니다.
개발자도구의 Network 탭에 들어가서 도대체 어떤 페이지에서 실시간 검색어를 쏴주고 있는지 확인해보겠습니다!
실시간검색어의 html태그 id가 bizKwdList였으니, Name을 정렬하여 biz로 시작하는 곳을 봐주었더니, 역시나 있네요.

Request URL을 복사해 페이지를 열어보면, 아래와같이 한글이 다 깨져서 나오긴 하지만, 키워드 리스트들이 들어가 있는 것처럼 보입니다.

인코딩을 utf-8로 설정해서 한글이 잘 보이도록하여 출력해보도록 하겠습니다.
|
1
2
3
4
5
6
|
# bizhotkwd 링크
url = 'https://www.nate.com/js/data/bizhotkwd_rel.js?v=202104061822&_=1619726235895'
req = requests.get(url)
# 인코딩 utf-8 설정
req.encoding='utf-8'
|

네.. 조금 더러워 보이긴 하지만 잘 들어가있네요.
이외에도 jsonLiveKeywordDataV1.js 라는 것도 있고, keywordList.today.json 라는 것도 있는데, 파일명이 실시간 키워드, 오늘의 키워드 뭐 이런 것 같아서 Request URL을 복사해서 한번 페이지를 열어보았습니다.
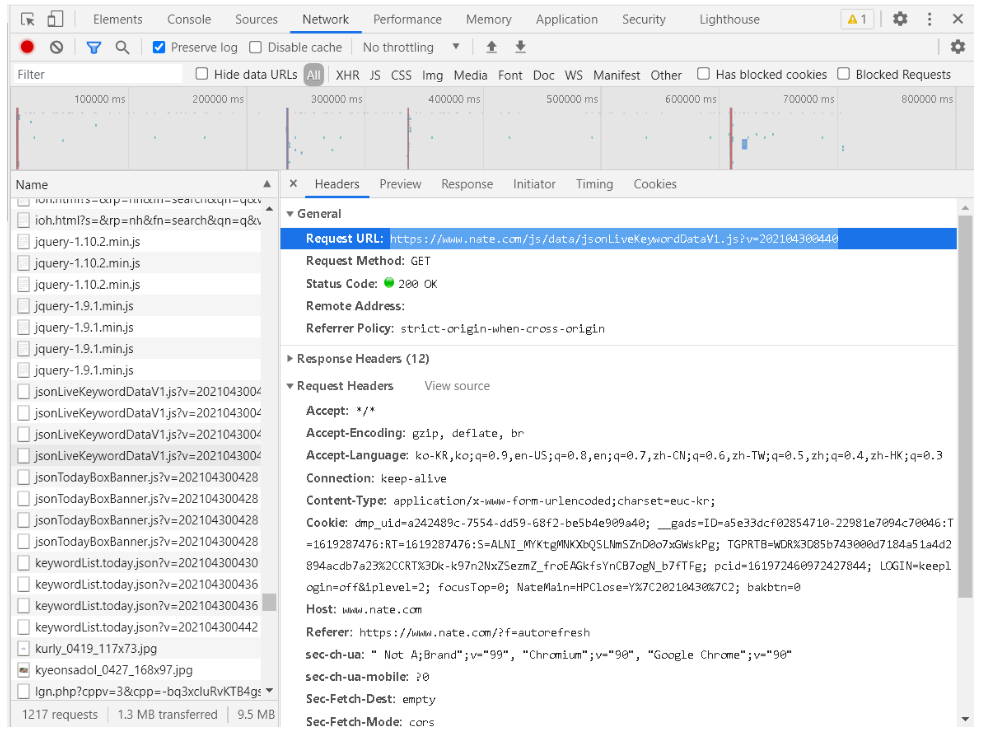
먼저 jsonLiveKeywordData URL인 www.nate.com/js/data/jsonLiveKeywordDataV1.js?v=202104300440 를 열어보면 다음과 같이 페이지가 열립니다. 뒤에 v파라미터값은 현재 시간이 넣어진 것 같아요.

오.. 너무나도.. 딱봐도 실시간 검색어인데요. 위에서 나온 키워드랑은 좀 다르네요.
keywordList.today URL인 www.nate.com/main/srv/news/data/keywordList.today.json?v=202104300430를 열어보면, 아래처럼 한글이 다 깨져서 나오긴 하지만, result: 200(정상호출), message: OK(오케이)와 서버시간, 서비시간, 데이터가 들어가있는 것이 보입니다. 키워드별로 언제, 그키워드가 얼만큼 검색이되었는지 까지 나와있는 듯 해요.

인코딩을 utf-8로 설정해서 한글이 잘 보이도록하여 json을 출력해보도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
|
# keywordList.today.json 링크
url = 'https://www.nate.com/main/srv/news/data/keywordList.today.json?v=202104300430'
req = requests.get(url)
# 인코딩 utf-8
req.encoding='utf-8'
# json형태로 가져와
req.json()
|

jsonLiveKeywordData 의 키워드들과 동일하나, 더 자세히 이슈시간과 얼마나 검색했는지까지 나와있는 듯 해요.
메인페이지를 자세히 보니 Biz. 인기 검색어와 실시간 이슈 키워드라는 것이 있어요. 인기 검색어만 집중해서 보느라 실시간 이슈키워드라는 것이 있는지 조차 몰랐는데 ( 보고싶은것만 보는.. )
인기 검색어를 가져오다보니 실시간 이슈키워드 까지 가져오게 되었습니다...!
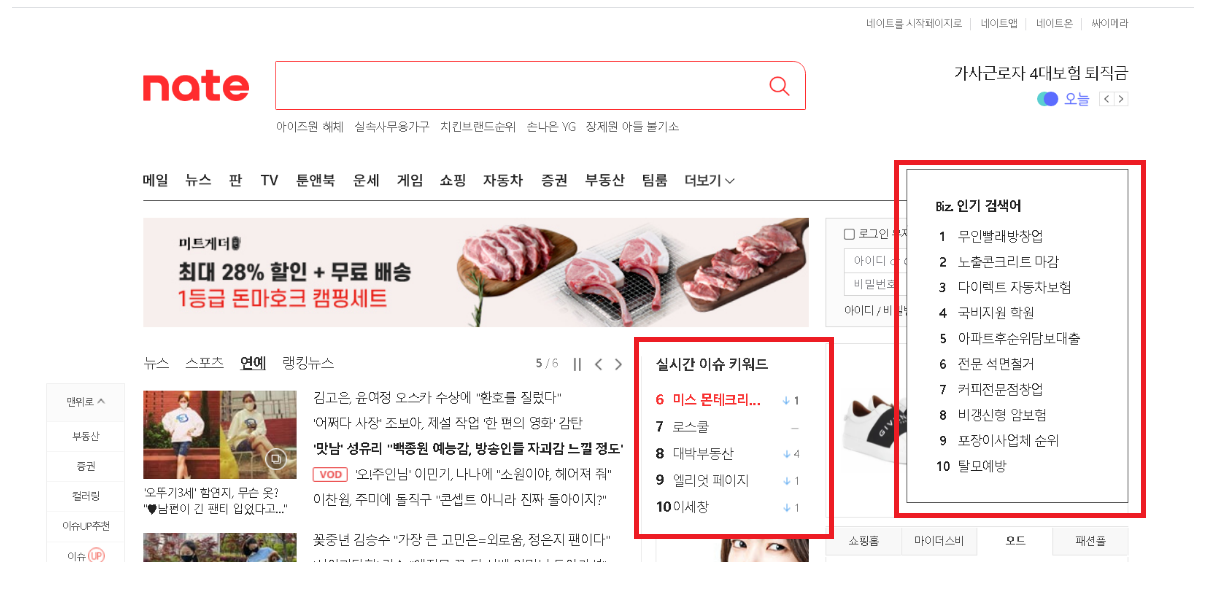
이렇게 네이트 인기 검색어만 가져오려다 실시간 이슈키워드 까지 가져오게된 크롤링.. 끝입니다!
'프로그래밍 > Python' 카테고리의 다른 글
| [pandas] 날짜를 일별, 주별, 월별로 구분하기 (2) | 2021.06.07 |
|---|---|
| [pymongo] 날짜별 데이터 수 가져오기 (find and aggregate) (0) | 2021.06.07 |
| [크롤링] 네이버 카페 크롤링(파싱) 하기 - 카페 소개 (1) | 2021.04.24 |
| 파이썬 Scripts 설치경로 (0) | 2021.04.20 |
| [oracleDB] python cx_Oracle 오라클DB 연결 (0) | 2021.04.14 |
